Interspeech 2026
Zero-VC: Zero-Lookahead Streaming Voice Conversion via Speaker Anonymization
1The Chinese University of Hong Kong, Shenzhen
2Shenzhen Loop Area Institute
3Shenzhen Transsion Holdings Co., Ltd.
4Amphion Technology Co., Ltd.
Abstract
Streaming zero-shot voice conversion struggles to disentangle timbre from linguistic content without degrading utility or inflating latency. Current methods rely on information bottleneck (IB) or speaker perturbation. While IB filters out timbre, it discards prosody, forcing models to explicitly inject features like fundamental frequency. This often requires buffering future frames, creating algorithmic lookahead latency. On the other hand, existing perturbation methods largely overlook the crucial trade-off between timbre leakage and utility preservation. Recognizing this neglected trade-off, we find that the inherent objective of Speaker Anonymization (SA) aligns well with balancing these factors. Thus, we introduce SA as a novel perturbation mechanism to explicitly mitigate timbre leakage while retaining prosodic utility. Crucially, SA's robust representations significantly alleviate the generator's reliance on future context, enabling our strictly causal, zero-lookahead network.
Method
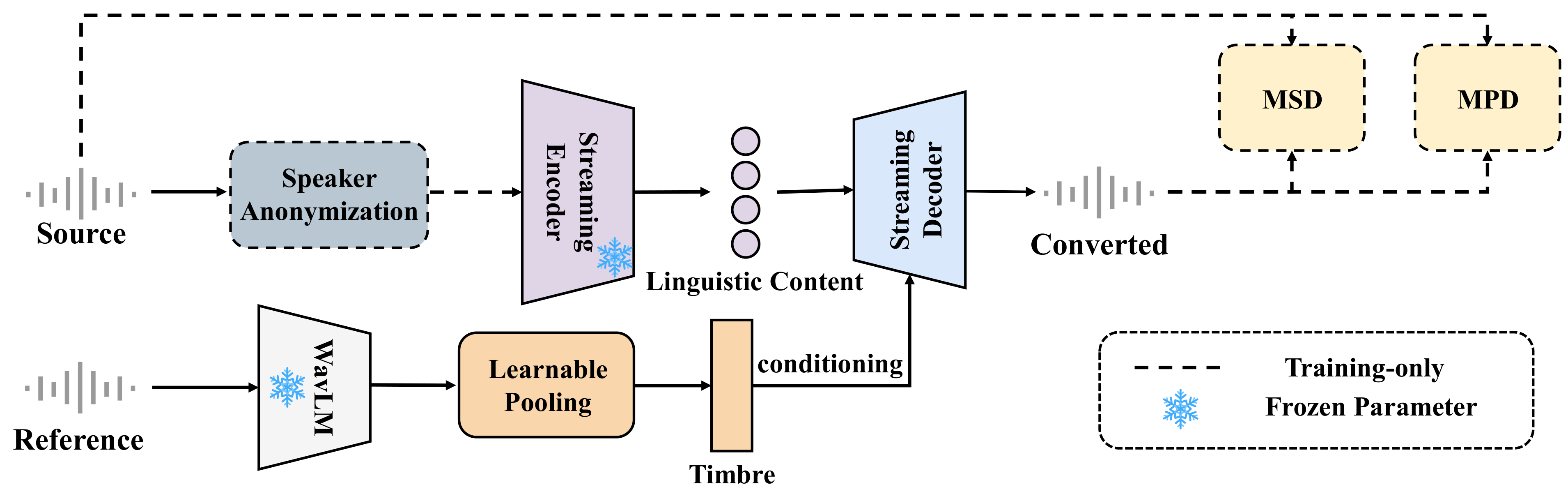
Zero-VC is a strictly causal, zero-lookahead streaming voice conversion system for hard real-time applications. Given a source utterance and a short reference clip from an unseen target speaker, it converts the source voice toward the target timbre while preserving linguistic content and prosody. Unlike many streaming VC systems that rely on information bottlenecks and explicit future-frame buffering for acoustic features, Zero-VC uses Speaker Anonymization (SA) instead, enabling one-frame-in, one-frame-out inference.
Overall Framework
The overall pipeline is shown in Figure 1. During training, source speech is first passed through an off-the-shelf SA module, which maps the utterance to a pseudo-speaker space and suppresses source identity while preserving temporal alignment, phonetic content, and prosody. The anonymized speech is then encoded by a pretrained streaming content encoder. A WavLM-based timbre encoder extracts a global speaker embedding from the target reference, which conditions a causal HiFi-GAN-style decoder. Adversarial training with MPD and MSD is used only during optimization; the SA, MPD, and MSD modules are discarded at inference time.
Samples
| Source Audio | Reference Audio | Zero-VC | CosyVoice | LSCodec | Seed-VC-Small |
|---|---|---|---|---|---|
Experiments
Zero-VC achieves strong objective and subjective performance while operating under a strict zero-lookahead streaming constraint. The following figures and tables summarize the main findings reported in the paper.
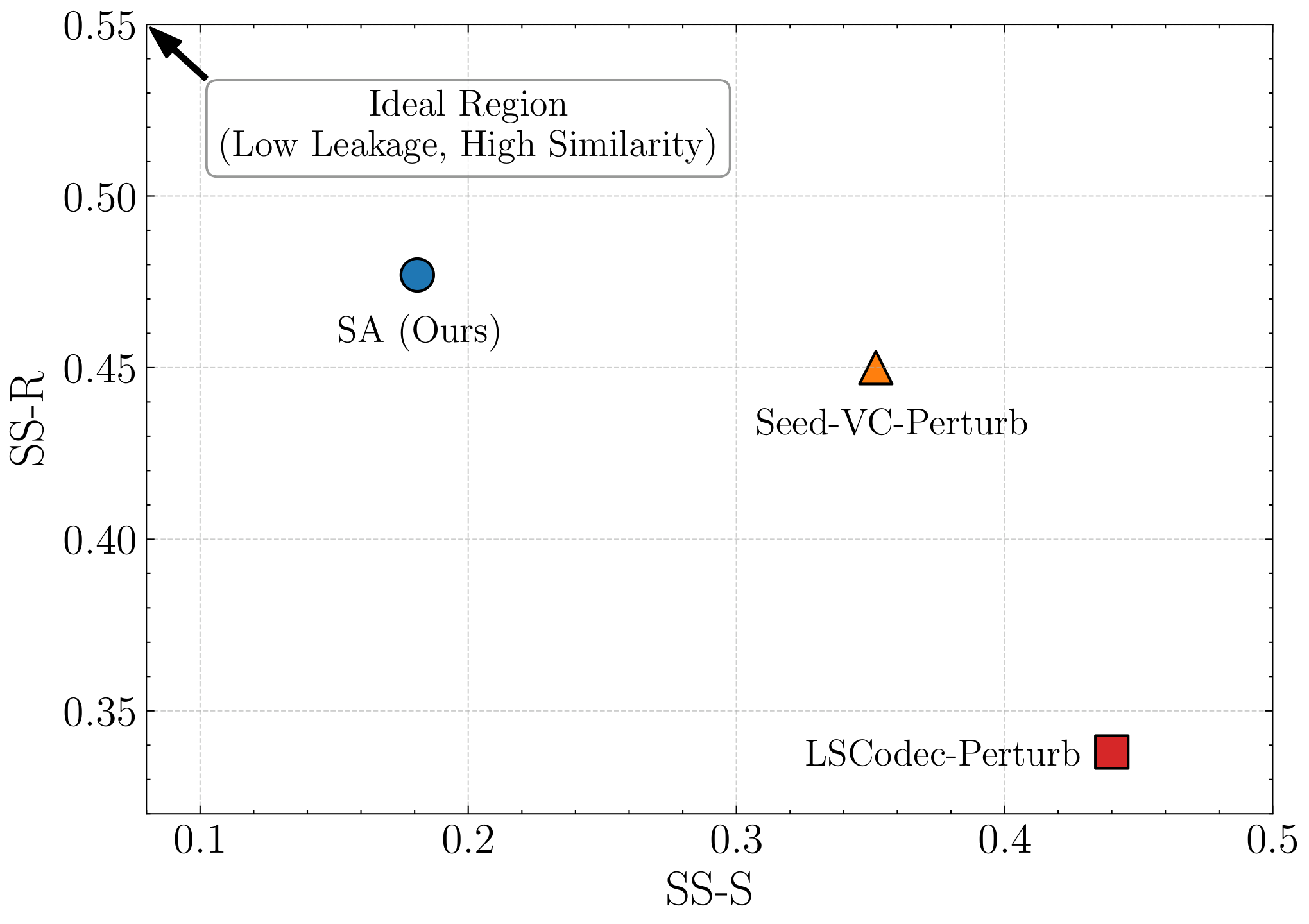
Balancing Source Leakage and Target Similarity
A core challenge in VC is to suppress source-speaker timbre leakage without hurting utility. Figure 2 plots speaker similarity to the source (SS-S, lower is better) against similarity to the reference (SS-R, higher is better). Points closer to the top-left corner indicate a more favorable trade-off. Compared with LSCodec-Perturb and Seed-VC-Perturb, SA-based training lies closest to the ideal region, achieving the lowest source leakage together with the highest target similarity.
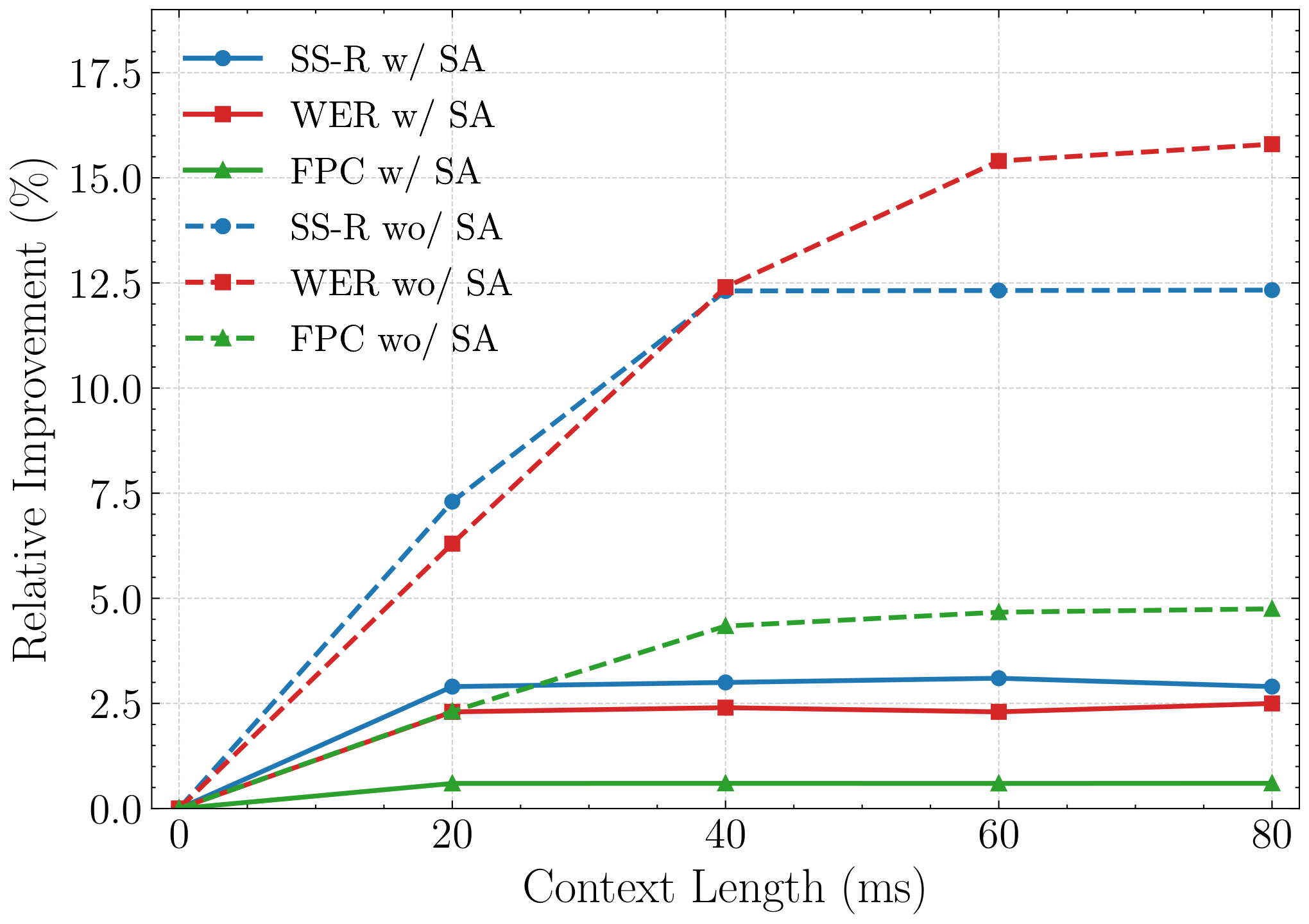
Reducing Lookahead Dependence
Figure 3 studies how much future context each model needs. For the model trained with SA perturbation (solid lines), performance saturates almost immediately at 0–20 ms of lookahead, with less than 3% relative improvement even when 80 ms of future context is provided. By contrast, the model without SA (dashed lines) still benefits noticeably from 40–60 ms of future frames. This supports our key claim: SA provides prosody-rich representations that reduce the decoder's dependence on future context, making a zero-lookahead architecture practical and effective.
Ablation Studies: Perturbation Strategies
To validate the superiority of SA, we compare intermediate audio evaluation and utility preservation trade-offs against baseline perturbation methods (LSCodec-Perturb and Seed-VC-Perturb).
Table 1 directly evaluates the perturbed intermediate audio. LSCodec-Perturb exhibits severe timbre leakage (SS-S = 0.704). Seed-VC-Perturb reduces this leakage (SS-S = 0.411) but causes a drop in prosody preservation (FPC = 0.688). SA effectively neutralizes source timbre, achieving an exceptionally low SS-S of 0.119, while better preserving the original prosodic contour (FPC = 0.718). Although the intermediate WER of SA is relatively high at this stage, downstream training (Table 2) shows that the model can still achieve considerable intelligibility, demonstrating that SA provides a robust foundation for disentanglement.
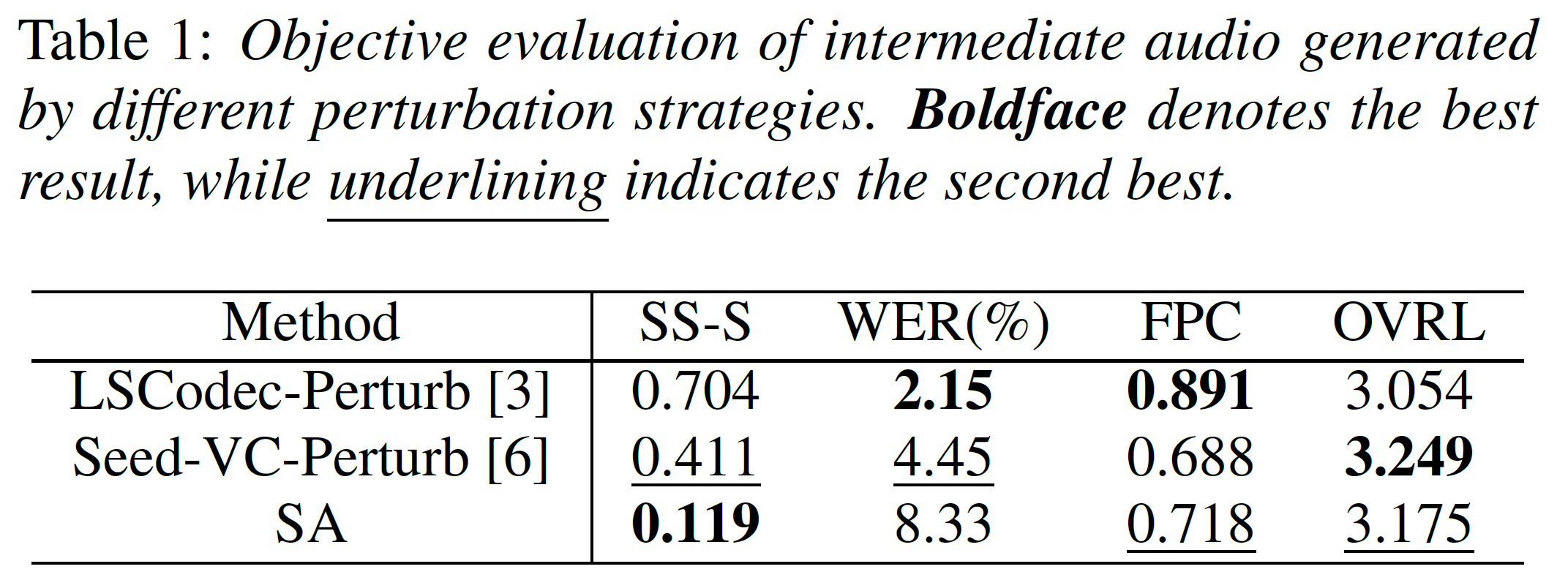
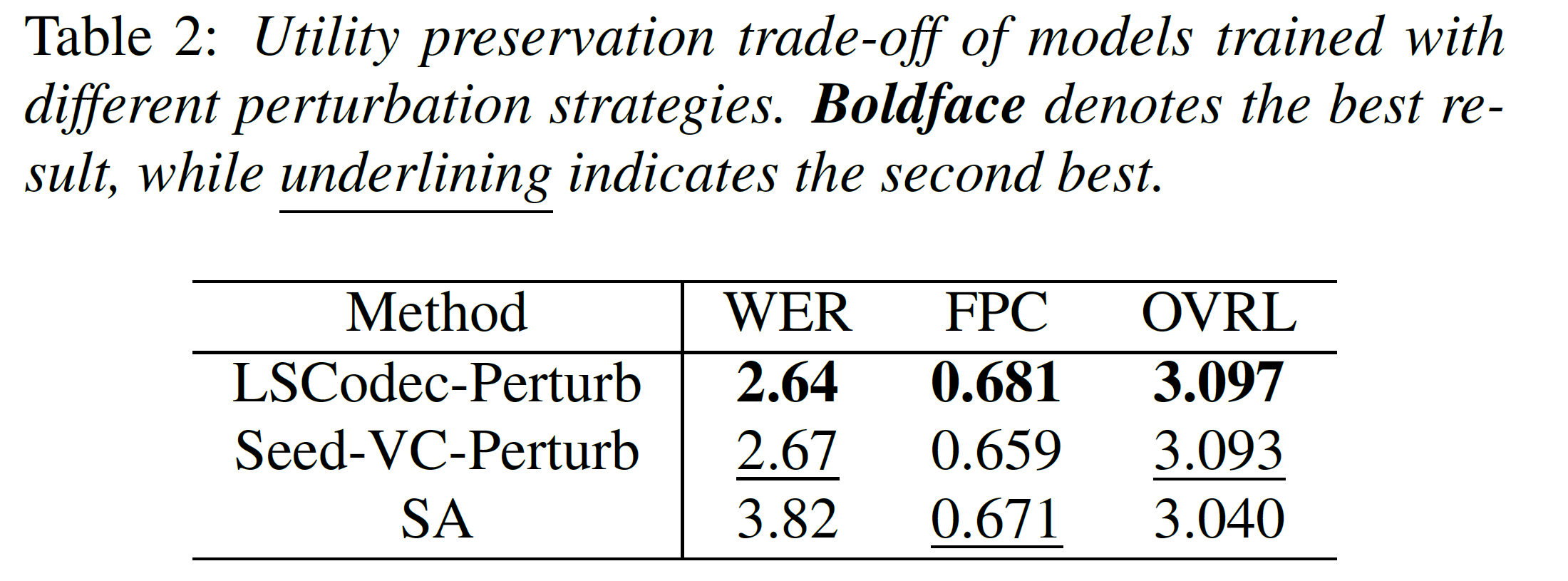
Table 2 evaluates the utility of models trained with each perturbation strategy on the final converted speech. While LSCodec-Perturb achieves the highest FPC, this metric becomes less meaningful when reference similarity is low—the model may largely reconstruct the source speech without effectively altering the timbre. In contrast, SA maintains competitive overall naturalness (OVRL = 3.040), closely comparable to the baselines, and ranks second on FPC (0.671). Together with the superior timbre decoupling shown in Table 1 and Figure 2, SA strikes a highly competitive balance between intelligibility, prosody, and high-fidelity timbre conversion.
Zero-Shot VC Performance
Table 3 summarizes zero-shot VC performance on the English subset of seed-tts-eval. Despite operating under a strict streaming constraint, Zero-VC achieves the lowest source similarity (SS-S = 0.171), the highest reference similarity (SS-R = 0.521), the highest subjective speaker similarity (SMOS = 3.88), and the highest prosody correlation (FPC = 0.688). It also remains the most efficient system with an RTF of 0.063 on CPU, outperforming all non-streaming baselines on timbre conversion quality.

Algorithmic Latency
Table 4 compares algorithmic latency among recent streaming VC systems. Zero-VC reduces latency to the single-frame theoretical minimum of 20 ms by avoiding future-frame buffering for acoustic feature smoothing, which is lower than DualVC3 (40 ms), RT-VC (47 ms), and StreamVC (60 ms). Note that algorithmic latency does not include inference latency.
